Less is More when it comes to AI
How we applied SDLC learnings to dogfood Bicameral
February 25, 2026
After taking in your perspectives on how AI codegen fits into the overall software development lifecycle in our previous post, we decided that it is time to break ground and begin building Bicameral.
Throughout this process, we used AI codegen extensively, and probably committed every SDLC sin in the book, which we were careful to document and compare against your comments.

This process taught us an important lesson: ruthlessly guarding noise vs signal production is crucial when it comes to effective AI tool use.
So in a space overcrowded with flashy tools, we will dedicate this article to outlining AI best practices that worked for us without relying on more tools.
1. Housekeeping for documentation
Our first finding is not a sexy one.
We encountered many instances in which the agents snuck in design choices from previous iterations, simply because we hadn’t updated our docs to reflect our latest thinking.
Once you have a comprehensive plan together… agents have a lot of issues zooming out… they get weighted down heavily by what already exists.
We knew going in that business context documents are needed for effective use of agents, but it did not strike us how much of a commitment it would be to constantly refresh our specs in order to capture the delta in product direction.
A simple meeting is sufficient to get a team of engineers to pivot towards a new sprint objective, yet coding agents need to be hand-fed curated pieces of information in order to perform well.
This calls for some housekeeping. We decided to deprecate all the research docs we had gathered over the past month (ouch!) in order to unclog agent context.
Context engineering as a practice has gotten a lot of attention lately, so we will link two perspectives that guided our approach:
The converging opinion on context management is that less is more. Hence, we created bite-sized decision docs for each subcomponent while keeping repo-level docs clear of implementation details. Doing so allowed us to trust the output more and, moreover, forced us to evaluate the relevance of previous decisions while prompting.
Agents are more likely to be derailed by stale designs than to come up with smarter solutions because of additional context.
2. It is easy to accidentally delegate decision-making to AI
The next one is more pernicious. Coding agents usually come with a “planning” phase, where feature scope and architectural recommendations are surfaced. But the important thing to note is that planning isn’t design, even though it is easy to conflate the two.
Broadly speaking,
- the planning phase is concerned with the what - scoping, research, etc. - which LLMs, built for efficient retrieval, excel at, whereas
- the design phase is concerned with how, a step that calls for judgment and discernment.
We learned first-hand the cost of inappropriately relying on AI in the design process. We wasted a week optimizing for better prompts while building Bicameral, only to throw it all away when my collaborator and I whiteboarded the end-to-end flow and concluded that an architecture lean in ML usage and mostly deterministic in nature would better serve our use case.
We pigeonholed ourselves into a suboptimal R&D path because our initial architectural intuition was not challenged. We were drowning in information that supported our initial view, but what we actually needed were questions that could challenge our whole premise:
“Perhaps we can consider static analysis and test how far we can get without relying on LLMs?”
The comment section highlighted this drawback of relying on LLMs to make high-level architectural decisions:
The goal of an LLM is not to give you correct answers. The goal of an LLM is to continue the conversation.
counterproposals and negative feedback are rarely up to snuff with something a staff level colleague would come up with
All that glitters is not gold: our coding assistants adopted our headspace and gave us conviction in what was a half-baked idea. They were trained to recognize patterns, after all, not break them.
Good design comes from out-of-the-box thinking.
That said, we cannot discount the AI findings that made their way into our eventual design. The ability to quickly pull up corroborating research in a niche domain and interactively cross-pollinate it with our internal data was nothing short of magic.
scoping, identifying pain points and planning - actually got massively better with coding agents.
So how do we get the best of both worlds?
In answering this, we are inspired by a study we came across, which looked into skill formation with AI use.
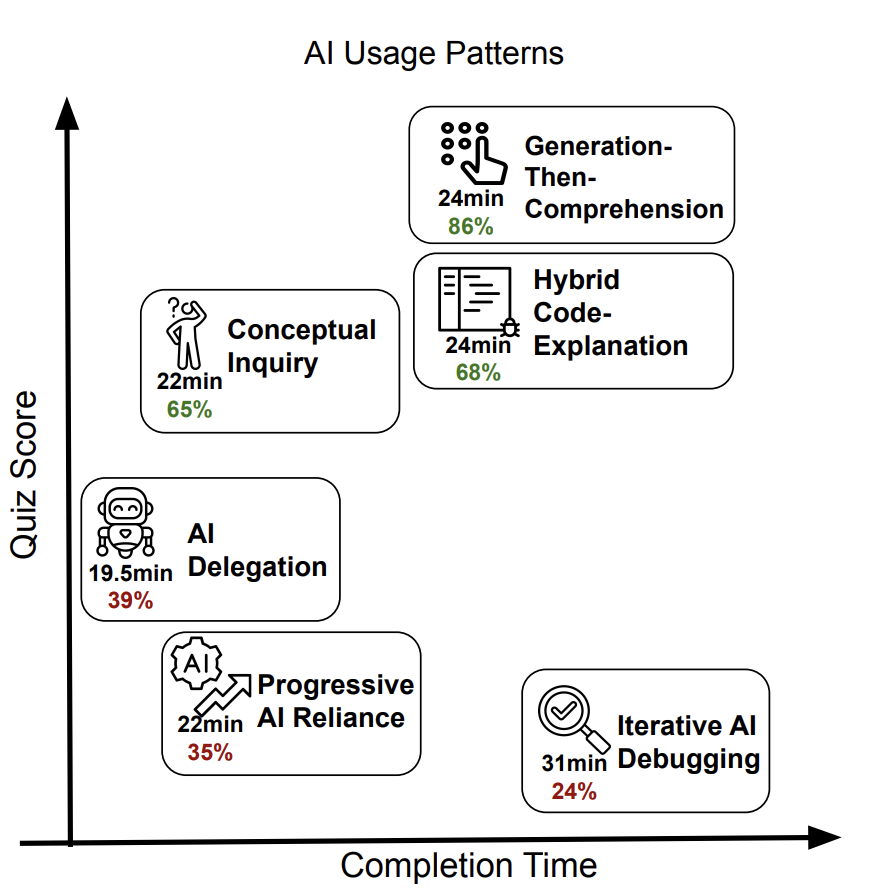
The study involves having participants complete a couple of coding tasks using a novel Python library, and then quizzing them afterward to assess their understanding.
The researchers found that the “generation-then-comprehension” style of AI use led to the most balanced outcomes in both completion time and learning, whereas iterative debugging resulted in slower completion and less understanding of the new library.
Participants in this group first generated code and then manually copied or pasted the code into their work. After their code was generated, they then asked the AI assistant follow-up questions to improve understanding. Shen, J. H., & Tamkin, A. (2026)
Concretely, the way we applied this learning was to make room for an explicit “prototype” phase between spec and implementation - where we give these state-of-the-art models free rein to implement their recommended approach, and then query them on each successive design choice they made and the trade-offs they were comparing.
We are careful to treat this as part of the planning phase, and discard the first round of output. Only after we have familiarized ourselves with the implicit decisions made by AI and specified our holistic judgment for each (i.e. partake in the design process), do we rewrite the prompt from scratch with the added context and ship the generated code.
A new plane of collaboration?
Realizing that AI assistants excel in initial research & eventual implementation - but not in between - led us to adopt a rather curious workflow internally:
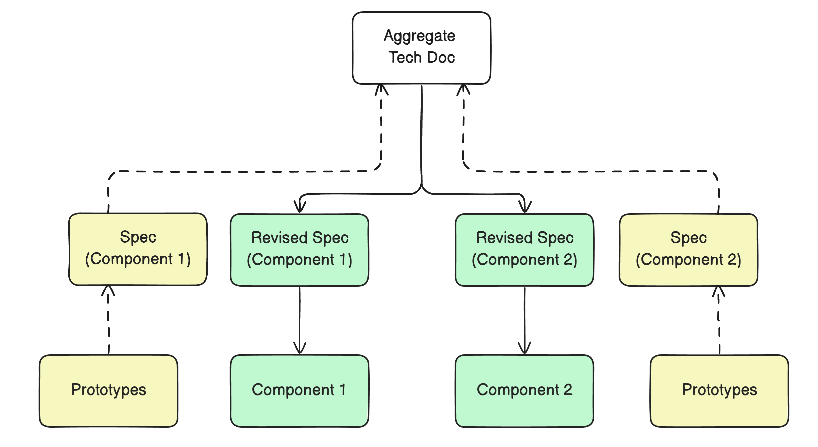
Specifically,
- we would first create a main tech spec, branch off from it (dashed line), and do some prototyping on our own, using this opportunity to discover and document constraints before merging our individual work back into the overall tech spec.
- then branch off again for the second time (solid line) to implement the actual code for the components each of us is responsible for.
Doing so uncovers the nooks and crannies of planned integration and allows us to decide on trade-offs ahead of time, reducing the frequency of hiccups in code review.
The irony, however, did not escape us: effective AI use requires devs to spend more time doing what they usually find tedious (documentation & coordination), and less of what they excel at (problem-solving).
Since we are currently a team of two, adapting our workflow to fit AI needs is straightforward enough, but we are well aware of the politics and conventions that devs in established teams have to contend with (to the folks on r/ExperiencedDevs - we hear you!).
This is what Bicameral sets out to solve. We aim to address the SDLC hurdles that make naive adoption of AI codegen a source of recurring headaches for developers.