Software Concepts for PMs in a hurry
A reference for how engineers think about scope
May 14, 2026
There are many primers out there on software concepts. This one is written specifically to assist PMs in scoping discussions — providing a lens to assess engineering tradeoffs so that there will be fewer timeline surprises and smoother feature rollouts.
We base this article on a seminal report on tech debt, as well as our Hacker News survey results.
When engineers say “this is more work than it sounds,” it’s usually for one of three reasons:
- it touches more layers than expected (“blast radius”),
- it undoes previous optimizations or conventions, forcing a tradeoff between competing properties (“refactor”), or
- they are simply misaligned on your product priorities and are going down rabbit-holes.
To help avoid scenario 3, we present a list of four software concepts behind the most commonly occurring categories of scope creep — especially now that AI can generate code at lightning speed:
- (misaligned) Service architecture
- (incorrect) Data flow pattern
- (complex) Database migration
- (inconsistent) Data modeling
(1 and 2 are presented in this article; 3 and 4 will follow in a part 2.)
Think of your engineers as navigating an ever-growing decision tree shrouded in fog, where certain wrong turns could be expensive to backtrack from.
Occasionally your engineers may have to zigzag across the board in order to not get pigeonholed down dead-ends. These are instances where your firm product input and timeline buy-in makes a world of difference.
At its core, this article reframes software engineering as change management from the perspective of product development.

Service architecture
The first and most familiar dimension is service architecture. You may be familiar with the two ends of the spectrum — monolith and microservices.
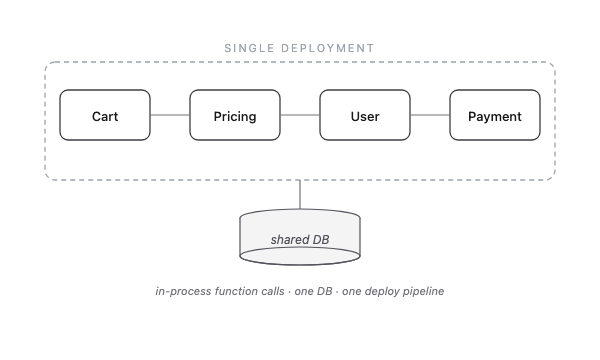
Monolith — one codebase, one deploy.
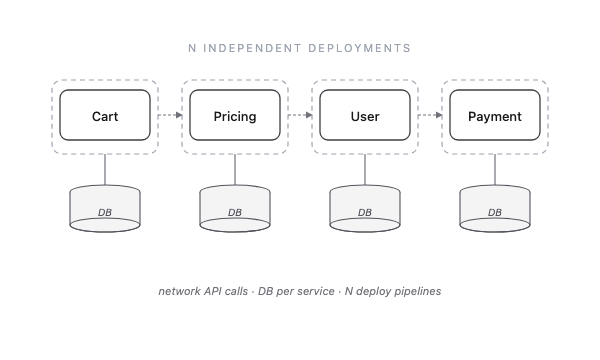
Microservices — many small services, each owning one job.
In practice, most production systems sit somewhere in the middle: a monolithic core handles the bulk of business logic, with a handful of microservices optimized for specific workflows.
The tricky part is deciding how to divide responsibilities between these services, an endeavor that is entirely dependent on the nature of the product being built. How aligned the dev team is on product priorities has lasting consequences on how fast features can be added in subsequent sprints.
Consider two possible splits for an e-commerce site:
- A divides by capability — Cart, Pricing, User, Payment each owned by a separate service.
- B divides by customer journey — one Checkout service owns the entire buying experience, and a Customer service handles other administrative workflows.
Seems arbitrary and relatively inconsequential right?
Watch how the same feature request gets trickled across the two architectures.
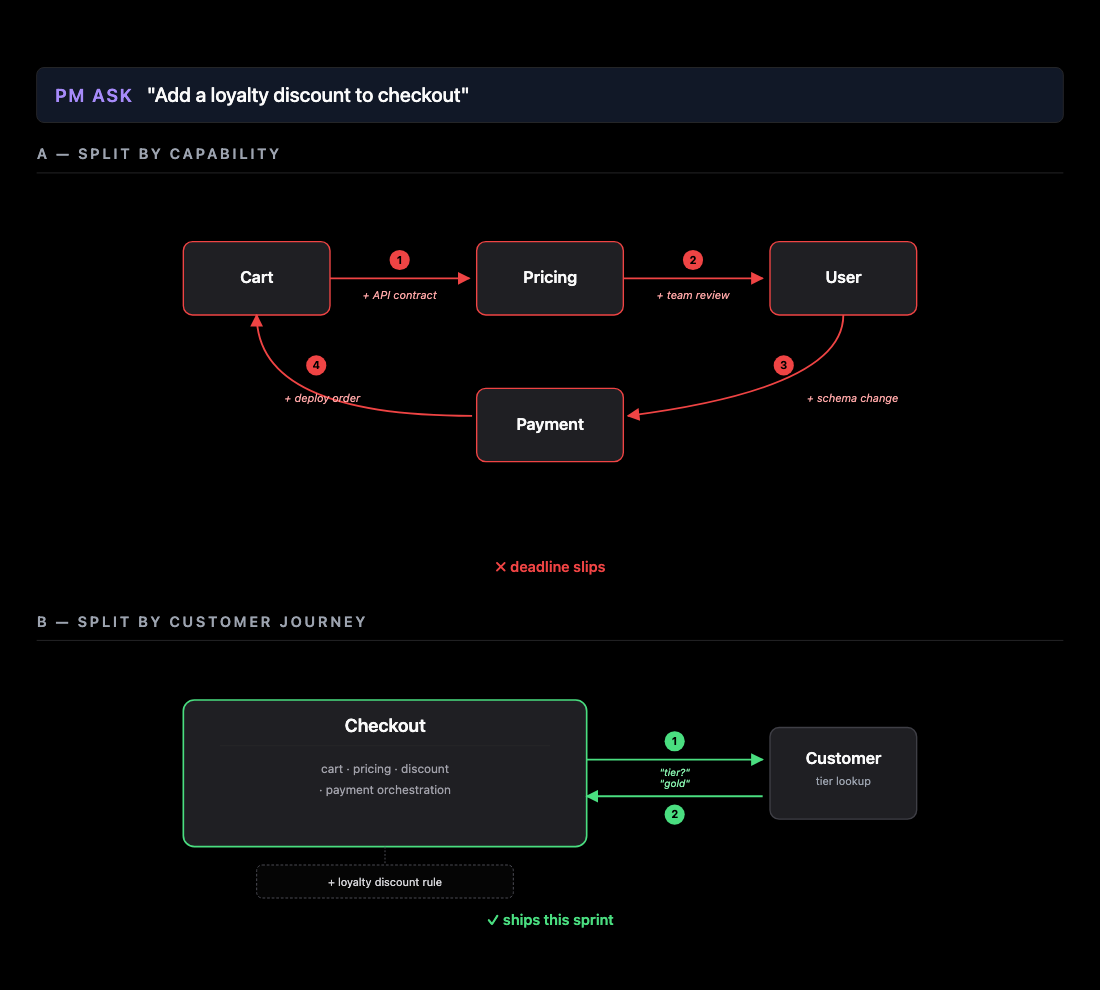
The edges indicate possible friction points coordinating changes across services (multiple PRs, aligning deployment versions, etc.). We see here that this simple feature request results in cross-cutting updates across multiple services in the first architecture, while only cosmetic changes are needed in the latter outside of business logic changes.
While AI codegen sped up code implementation, it is this developmental overhead that really cuts deep.
Now suppose we try a different request — integrating with a new payment provider.
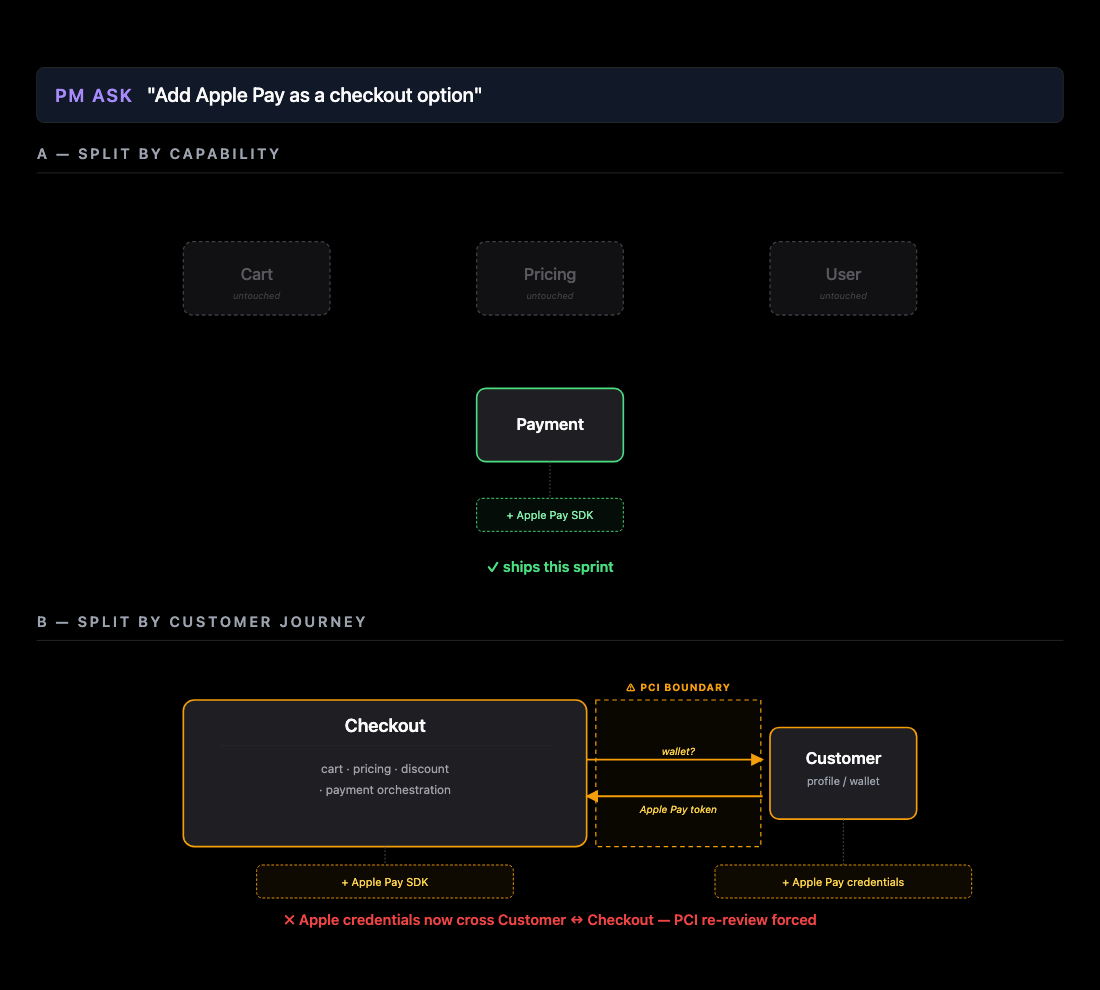
The capability-split architecture allows payment integration to take place independently without much hassle, whereas the alternative architecture forces a reassessment of security and data model.
Same two arrangements, completely opposite outcomes.
- A is optimized for integrations — if you have product-market fit and would like to go broad, splitting services by capabilities allows for backend composability.
- B is optimized for experiments — if the shape of the product is not yet fixed, splitting services by customer journey allows each workflow to be tweaked with minimal damage.
Neither is right by default; but without alignment between architecture and product roadmap, sprint velocity may become highly unpredictable. In fact, this is what constitutes “tech debt” — misaligned expectations calcified in code.
Of course, the ideal scenario is that PMs wouldn’t have to worry about implementation details and can trust the dev team to make the right judgment. As such, conveying the why behind feature requests, walking engineers through your thought process, goes a long way in ensuring you get fewer surprises in scoping.
Data flow pattern
The next dimension to consider is how services talk to each other. This is also an aspect largely dictated by product needs — but in place of the longer-term roadmap, it has more to do with the minutiae of UX.
We will explore how one particular pattern, the push vs pull model, impacts data latency. This quality is crucial to nail down in fintech or cybersecurity, where immediate updates are part and parcel of the product offering.
- Pull (polling) — the client controls timing. Simple to implement and maintain, but not scalable, and slow.
- Push — the server controls timing. Real-time updates that scale, but complex to maintain.
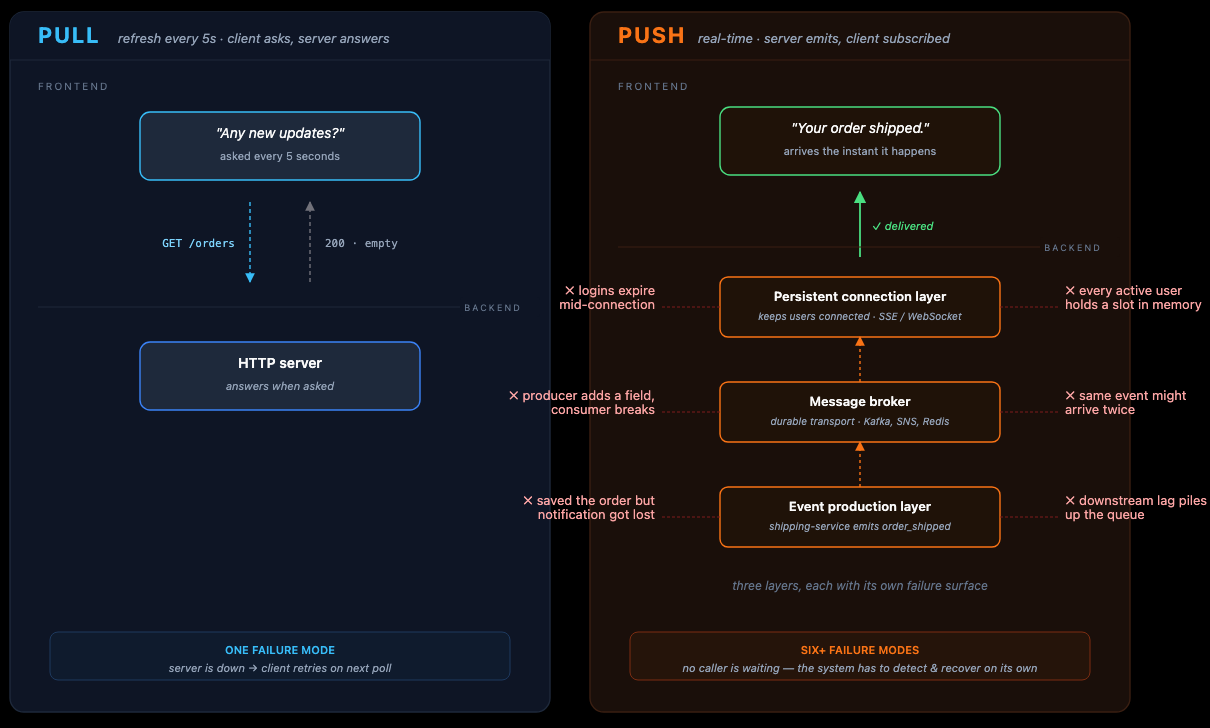
The diagram above illustrates how a small distinction in latency requirement (from 5s to real time) requires a complete rework of infrastructure and the introduction of multiple layers of infrastructure.
Let us briefly examine why these layers need to be added to support push-based data flow:
- Event production layer — packages events in standardized formats to be shared across layers.
- Message broker — ensures updates don’t get lost when services go offline. Kafka, SNS, Redis.
- Persistent connection layer — keeps an active connection with the frontend to push updates. SSE / WebSocket.
On a high level, these layers are put in place to handle potential failure cases.
Imagine picking up a takeout from a restaurant yourself (pull) vs. ordering it via delivery (push). The 20 minutes saved for you necessitates an entire infrastructure of order management, driver matching, and customer service be put in place in order to deal with the potential ways things could go wrong.
What does this mean practically for feature scoping?
Some aspects of user flow benefit from firm commitments early on (whenever possible) in order to prevent costly rework.
A marginal improvement in user experience may incur extra infrastructure that sucks up dev hours. Conversely, if it is a non-negotiable requirement to begin with, there is also a switching cost associated with not making the right investment the first time around — services would have been built around the incorrect data flow model, requiring the cross-cutting changes down the line.
Concluding remarks
Now that AI has automated the first-order task of writing code, software engineering will evolve more and more towards tackling the second-order task of delivering rapid updates without regression — i.e. change management.
In this new paradigm, ensuring that the dev team is aligned on both the firmness of low-level requirements and the broader context surrounding product evolution becomes even more important, as it now determines whether the right enabling architectures are put in place to benefit from AI-assisted development.
Subscribe to the Bicameral newsletter to receive notification for part 2 of this article.